Team
Court Logic is built by a multidisciplinary team of UC Berkeley MIDS graduate students, combining deep expertise across product management, machine learning, legal domain knowledge, and cloud infrastructure.

Chad Vo
UI/UX Engineer & Data Product Manager
10 years of experience
Business Development & Private Equity

Peter Liu
ML/AI Engineer & Data Scientist
25+ years of experience
Software, Data & System Engineering

Carla Tapia
ML/AI Engineer & Domain Expert
6 years of experience
Data Engineering & Legal Domain

Moonsoo Kim
Backend Engineer & AWS Administrator
10 years of experience
Product & Technology Consulting
Problem
The United States Supreme Court has shaped the trajectory of American laws since its establishment in 1700s; yet, its decision-making process remains unclear and opaque to the general public, even to experienced level professionals. Historically, oral arguments span hours of legal reasonings across numerous judicial philosophies. Therefore, written opinions often can be quite lengthy, which lead to a continuously-widening gap between Court's output and public comprehension.
Currently, many existing legal prediction tools on the market treat the US Supreme Court as a black box, where they ingest cases' metadata and provide outputs mainly as binary predictions. These tools tend to not provide great explanations on why justices might rule a certain way, how coalition dynamics may shift the outcome, and what doctrinal tensions may drive a split decision. As the result, there is not a truly interactive system that allows users to pose a constitutional question and receive a structured, multi-perspective simulation on how the existing justices bench would deliberate. Those reasons leave our team some room to build our product, Court Logic, to address this gap directly.
Our platform is a multi-agent AI platform that simulates Supreme Court oral arguments in real time, where users can submit any legal question or description and receive a full adversarial debate either between ideologically distinct coalitions, Liberal versus Conservative, or from their selected custom personas. Afterward, a well-trained Chief Justice agent would then preside over the proceedings and present arguments across all rounds and deliver a court-like structured opinion with great details such as vote tallies, majority reasonings, concurrences, and dissents.
Target Audience & Market Opportunity
Court Logic sits at the intersection of two rapidly expanding markets: generative AI adoption and legal technology enablement. The convergence of these trends creates a substantial opportunity for an AI-powered platform that makes judicial reasoning accessible, interactive, and explainable.
2.4B
GenAI Users Worldwide
65% enterprise adoption rate
ITU, Feb 2026
1.3M
U.S. Licensed Lawyers
Across 450K+ law firms
American Bar Association, Jan 2025
$6.1–6.6B
Legal Enablement Market
Annual spend on legal tech
Industry estimates, Dec 2025
Our primary target users include law students and educators seeking interactive tools to explore constitutional reasoning, legal researchers and practitioners looking to quickly simulate how the current bench might deliberate on emerging issues, and civic-minded professionals who want to understand Supreme Court dynamics without wading through hundreds of pages of legal opinions. By combining generative AI with retrieval-augmented generation grounded in real judicial writing, Court Logic bridges the gap between raw legal data and actionable, multi-perspective insight.
Data Pre-Processing & Pipeline Setup
Our data pipeline is built end-to-end on AWS, with Amazon S3 as the central storage layer and FAISS as the vector retrieval engine.
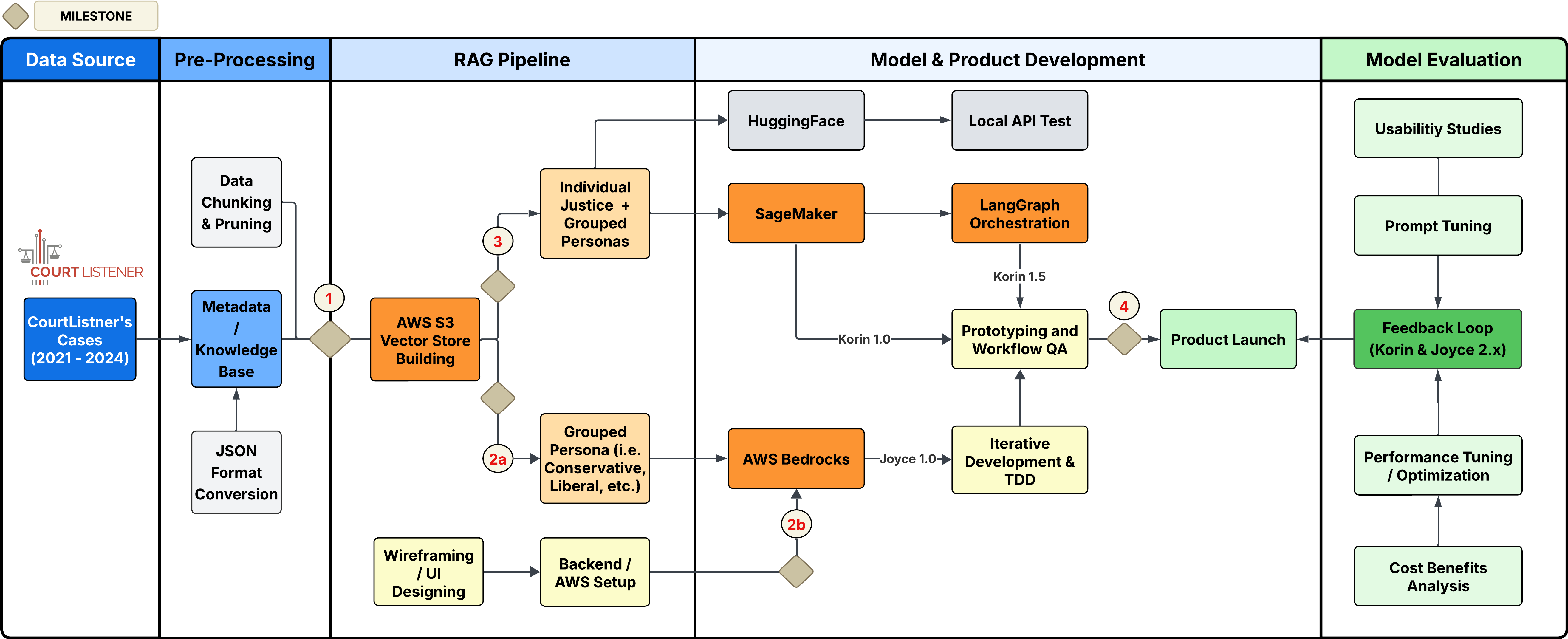
2.1 Source Data Ingestion
For training data, we used only completed Supreme Court opinions from Court Listener between 2021–2025, which were imported into a local data frame through the provided API. Since the data arrived quite raw, it has to go through several preprocessing stages before it can be utilized by the simulation engine and evaluation pipeline.
Using a seeding script, our team converted all opinions and stored them as a structured JSON document containing case name, year, opinion, case type, and the full text, which then uploaded into AWS S3 as the central storage.
2.2 Data and Text Normalization
All opinions used to train our models are cleaned and split into semantically meaningful chunks as the RecursiveCharacterTextSplitter preserves paragraph boundaries and legal citation patterns while ensuring chunks fit within embedding model token limits. Each chunk would retain metadata such as case_name, justice_id, opinion_type, and s3_key, which enable tracking through the entire retrieval and generation pipeline.
2.3 Vector Store Construction
For the latest deployed model, our pipeline executes a six-stage process:
- Downloads all opinions from S3, organized by justice
- Chunks text using a recursive character splitter with configurable chunk size and overlap
- Embeds chunks via the configured provider (Amazon Titan Embed v2, Cohere Embed v3, or SageMaker-hosted sentence-transformers)
- Builds per-justice FAISS indices for individual retrieval
- Merges indices into coalition-level stores: Liberal (Sotomayor + Kagan + Jackson), Conservative (Thomas + Alito + Gorsuch + Kavanaugh + Barrett + Roberts), and a Combined index for the Chief Justice
- Caches indices locally and uploads to S3 for production use
At inference time, each coalition agent queries its merged store to retrieve the most relevant past opinions, grounding every argument in real judicial writing.
2.4 Gold Standard Outputs
For our evaluation stage, we rely heavily on a curated dataset of 2024–25 Term decisions with each case includes the case name, summary, question presented, vote split with ideology label, short outcome, structured opinion blocks (majority, dissent, concurrences), and per-block key points (5–8 holdings per opinion). As a result, this dataset serves as ground truth for all evaluation metrics.
The gold standard dataset was enriched with the outcome_short field — a concise, parseable outcome label in order to improve metrics accuracy. Our earlier evaluation runs revealed that long-form outcome narratives introduced ambiguity in automated extraction. Thus, the addition of this field resolved outcome classification accuracy issues in the evaluation pipeline.
2.5 Embedding Generation
As we experimented with different backend infrastructure, which led us to our latest and live model, three embedding providers are supported, selectable via environment configuration:
| Provider | Model | Use Case |
|---|---|---|
| AWS Bedrock | amazon.titan-embed-text-v2:0 | Production default |
| Cohere | cohere.embed-english-v3 | App Runner deployment |
| SageMaker | Custom sentence-transformers endpoint | Self-hosted inference |
Embeddings are generated in batches with 32 documents per request for SageMaker and 96 for Cohere, which are then indexed into per-justice FAISS stores. Coalition stores are then constructed by merging individual indices, enabling a single retrieval call to surface opinions from multiple justices simultaneously.
Backend Architecture
Court Logic is deployed on a fully managed AWS stack. The architecture divides responsibilities between two deployment targets: AWS App Runner for the user-facing web application and Amazon SageMaker for the Korin simulation engine.
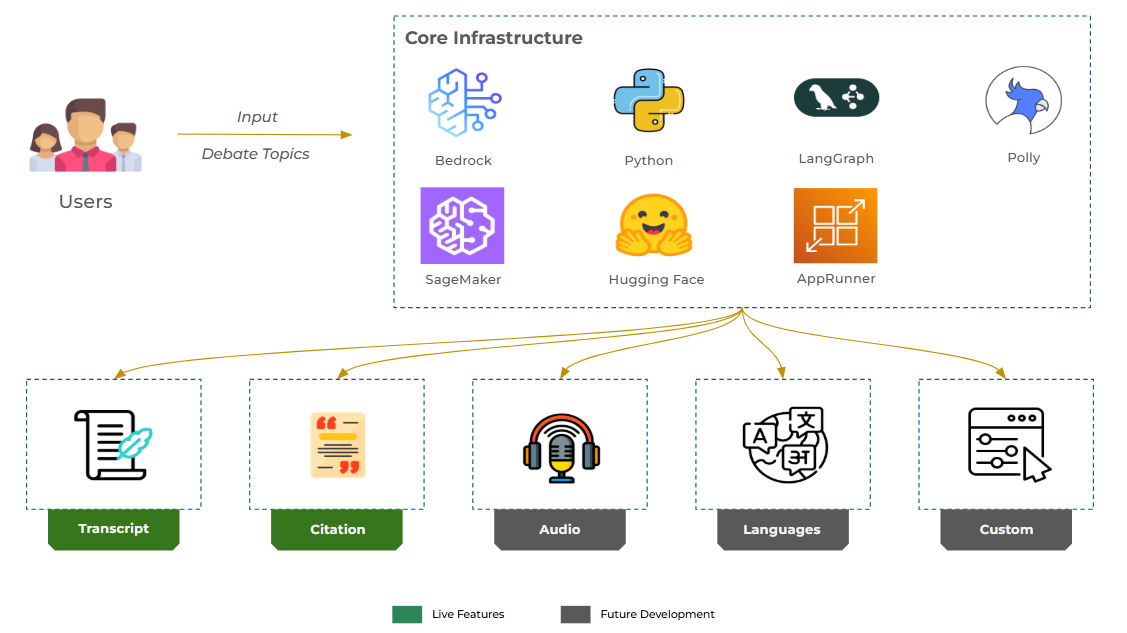
4.1 AWS Configuration
App Runner Deployment
The Flask application is containerized via Docker (python:3.11-slim) and deployed to AWS App Runner. Runtime configuration: Gunicorn with 4 workers, 2 threads per worker, 120-second request timeout, auto-scaling managed by App Runner. Over 20 environment variables are configured via apprunner.yaml covering LLM provider selection, Bedrock agent IDs, S3 bucket references, and TTS API keys.
Multi-Provider LLM Factory
The llm.py module implements a factory pattern supporting three inference backends, all implementing the LangChain BaseChatModel interface. Provider switching is controlled by a single environment variable (LLM_PROVIDER), enabling the same codebase to run against any backend without code changes.
| Provider | Models | API |
|---|---|---|
| AWS Bedrock | Claude 3.5 Sonnet, Cohere Command R, Nova Lite, Titan, Llama 3.1 | Bedrock Converse API |
| SageMaker | HuggingFace TGI, Amazon Titan, Cohere Command | Real-time endpoint |
| HuggingFace | Phi-3.5-mini-instruct | Inference API or local pipeline |
Security & Audit
All inter-service communication uses IAM role-based authentication. The web UI is protected by a session-based password gate. Request audit logs are written asynchronously to S3 without blocking inference, enabling debugging, reproducibility, and compliance tracking.
4.2 SageMaker / Bedrock
Amazon SageMaker
The Korin simulation engine is deployed as a SageMaker real-time endpoint via a FastAPI server. The endpoint exposes health checks (/ping), synchronous simulation (/invocations), SSE streaming (/invocations/stream), and metadata endpoints for available justices, tone levels, and detail levels. The SageMaker container includes the full LangGraph stack and is pushed to Amazon ECR for deployment. Read timeout is set to 300 seconds to accommodate multi-round simulations.
Amazon Bedrock
Bedrock serves as the primary LLM and embeddings provider in production:
- Bedrock Converse API — Model-agnostic chat interface supporting Claude, Cohere, Titan, Llama, and Mistral through a unified request schema
- Bedrock Agents — Three managed agents for the Joyce debate system: Conservative Agent (Amazon Nova Lite), Liberal Agent (Amazon Nova Lite), and a Judge Agent for verdict rendering
- Bedrock Flows — Managed flow orchestration for multi-round debate sequences
- Bedrock Embeddings — Amazon Titan Embed Text v2 and Cohere Embed English v3 for vector store construction
Production model configuration on App Runner uses Cohere Command R v1 for generation and Cohere Embed English v3 for embeddings.
4.3 Amazon S3 Storage
Amazon S3 serves as the persistent storage layer for all platform data, organized into four functional prefixes:
- opinions/ — Raw justice opinions as individual JSON files, one per case per justice, enabling granular updates without full knowledge base rebuilds
- vectorstores/ — Pre-built FAISS index files. At deployment time, the platform loads pre-built indices from S3 rather than rebuilding from raw opinions — reducing cold-start time from minutes to seconds
- requests/ — Audit trail with per-request logs organized by date and session ID, written asynchronously via background threads
- experiments/ — Evaluation outputs with full provenance (timestamp, endpoint mode, per-case metrics, and aggregate summaries) enabling reproducible evaluation runs
Product / Features
5.1 Main Agent Flow
Court Logic's simulation engine is built on LangGraph, a framework for orchestrating stateful multi-agent workflows with conditional routing and streaming support. In order to showcase the evolution of our models, we built a model selection feature that allows users to test any of the models we ever deployed.
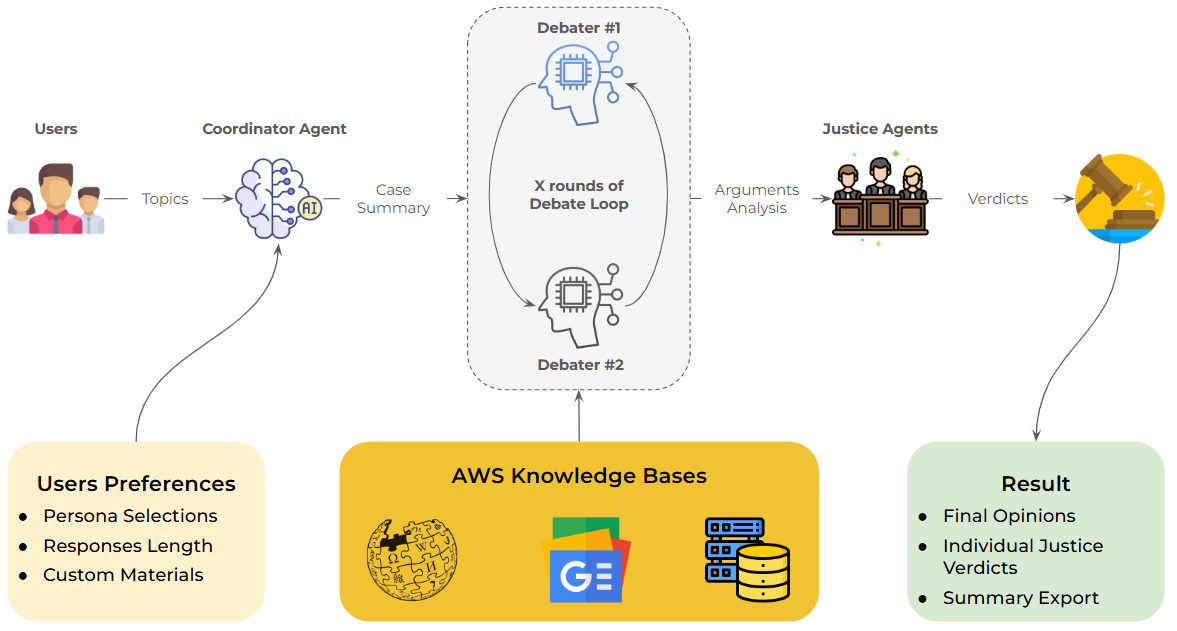
Joyce 1.0: Bedrock Agent Debate Flow
For our first model, we experimented with AWS Bedrock agents and built agents, Conservative and Liberal Agent, both powered by Amazon Nova Lite. With our Python script, the system would then orchestrate a three-round adversarial debate with a selected topic of user's choice. After all rounds, a Judge Agent evaluates the full transcript and renders a verdict with a winner, key findings, and ruling.
Korin 1.0: Individual Justice Mode
After a short experiment with Joyce 1.0, we quickly discovered that Bedrock acted as a black box due to its lack of visibility. Therefore, there were great challenges while fine-tuning the agents and evaluation process. Additionally, it was quite costly to operate even during the testing phase so we decided to pivot our product using SageMaker.
With SageMaker, we have the ability to build and train all of our agents to our preferences due to its flexibility. For Korin 1.0, with the exact replicated workflow as Joyce 1.0, each justice operates as an independent agent with a detailed persona prompt encoding their judicial philosophy, a dedicated FAISS retriever querying only their past opinions, access to research tools (Wikipedia, Google News) for contemporary context, and tone/detail parameters controlling output complexity.
At the end, during the debriefing session, Chief Justice Roberts agent frames the constitutional questions, each selected associate justice responds in turn, and after three rounds of deliberation, the Chief delivers a structured opinion with vote tallies.
With Korin 1.0, we are able to manage the cost much more efficiently and achieve a more accurate and more efficient workflow. Yet, since we call up to 9 to 11 agents per prompt, the cost remains somewhat elevated and each debate can be quite lengthy, leading to potential poor user experiences.
Korin 1.5: Coalition Mode (Production Default)
As a more refined version of Korin 1.0, we made a decision to blend the two previous approaches, which simplifies the debate into two coalition agents plus the Chief Justice. Each coalition speaks with one voice representing its constituent justices:
- Liberal Coalition — Channels Sotomayor, Kagan, and Jackson. Prioritizes civil rights, real-world impact, and equal protection.
- Conservative Coalition — Channels Thomas, Alito, Gorsuch, Kavanaugh, and Barrett. Prioritizes originalism, textualism, and structural federalism.
- Chief Justice Roberts — Opens the case, synthesizes arguments across rounds, and delivers the final opinion with vote split and rationale.
Just like the other models, in each round, both coalitions present arguments grounded in their merged vector stores, and the Chief Justice synthesizes their positions before opening the next round. After the final round, the Chief delivers a structured opinion including the holding, vote tally (e.g., 6–3), majority reasoning, concurrences, dissents, and practical impact. In addition, we also built an additional workflow that allows users to dial in individual justice's opinion instead of automatically calling these agents so we can reduce costs and processing time.
Presenting the results this way, we are able to provide additional visibility into the decision making process behind each outcome without compromising too much on our budget and cost per debate.
Tone & Detail Configuration
For additional enhancement, we implemented a preferential setting that allows users to choose how detailed and thorough the output they want to be with the detail levels control response length: brief (~50 words, one key reason) or in-depth (~200 words, full reasoning with precedent).
| Level | Label | Register |
|---|---|---|
| 1 | The Civic Observer | Plain language, no jargon, relatable analogies |
| 2 | The Analytical Student | Foundational concepts defined, light citations |
| 3 | The Procedural Apprentice | Standard legal terminology, doctrinal frameworks |
| 4 | The Strategic Advocate | Precise doctrinal language, strategic framing |
| 5 | The Legal Arbiter | Formal judicial register, exhaustive citation, footnotes |
5.2 Usability Studies
Aligning with our mission statement, the platform's user experience was designed for accessibility across diverse audiences, from law students exploring constitutional reasoning to researchers evaluating AI judicial prediction.
Standard GenAI Web Interface
The frontend is a responsive, single-page application built with Tailwind CSS, JavaScript, and Server-Sent Events for real-time streaming with the following key features:
- Model Selector — Switch between Joyce 1.0, Korin 1.0, and Korin 1.5 with a dropdown
- Persona Selection — Modal with search, validation, and auto-suggestions based on the submitted topic
- Real-Time Debate Panel — Slides in from the right with color-coded message bubbles (blue for conservative, purple for liberal, gold for Chief Justice)
- Typing Animation — Character-by-character rendering with configurable speed that respects HTML tags
- Smart Suggestions — Auto-generated persona recommendations tailored to the legal domain of the question
- Dark Mode — Full theme support with smooth transitions
- Responsive Layout — Sidebar collapses to icons on tablets; debate panel goes full-width on mobile
Podcast Generation
To make Court opinions accessible beyond text, the platform includes a podcast feature, which is made available after any simulation. Users can generate an AI-powered podcast where two hosts, Peter and Hailey, discuss the opinion in a conversational, accessible format. Audio is synthesized primarily via ElevenLabs and Amazon Polly as a fallback option, delivered as a downloadable MP3.
Onboarding & Help
A tutorial modal walks new users through the platform with a step-by-step guide covering model selection, persona configuration, starting debates, and interpreting results. An FAQ accordion addresses common questions. Simulation controls allow users to configure tone level, detail level, and scroll speed from a dedicated settings panel.
5.3 Evaluation
For evaluation, we decided to combine automated metrics, LLM-as-a-judge scoring, and RAGAS retrieval quality assessment. All evaluation results are persisted to S3 for reproducibility.
Automated Metrics
| Metric | Method | Measurements |
|---|---|---|
| Outcome Accuracy | 12-step heuristic extraction | Does the predicted ruling (affirm/reverse) match the gold outcome? |
| Ideology Alignment | Vote block parsing + justice mapping | Does the predicted majority coalition match the gold ideology label? |
| Key-Point Coverage | Significant-word matching (50% threshold) | What fraction of gold key points appear in the prediction? Reported separately for majority and dissent. |
| Dissent Detection | Binary pattern match | Does the prediction include dissenting language when the gold answer has a dissent? |
| Vote Accuracy | Regex extraction (e.g., "6-3") | Does the predicted vote split match the gold split? |
LLM-as-a-Judge Similarity
A dedicated LLM evaluator scores the similarity between predicted and gold opinions on a 1–5 scale across five dimensions: reasoning alignment, key-point coverage, ideological fidelity, cited precedents, and overall conclusion. Scores range from 1 (completely different) to 5 (nearly identical in reasoning, structure, and conclusion).
RAGAS Retrieval Evaluation
The RAGAS framework measures retrieval quality across three evaluation modes:
| Mode | What It Evaluates | Ground Truth |
|---|---|---|
| Coalition | Liberal & Conservative FAISS stores | Key points from relevant opinion blocks |
| Concurrence | Individual justice stores | Points from named concurrences |
| Combined | Chief Justice's merged store | All key points across all opinion blocks |
Metrics include context precision, context recall, faithfulness (end-to-end), and answer relevancy (end-to-end). A custom JSON sanitization layer handles Bedrock Claude's tendency to wrap JSON responses in markdown fences, ensuring reliable metric computation.
Evaluation Results
We conducted 22 evaluation runs between March 2 and March 22, 2026, iterating on embedding models, chunk sizes, chunk overlaps, retrieval depth (k), Graph RAG, and prompt tuning. All runs were evaluated against the same 13-case gold standard dataset from the 2024–25 Supreme Court Term.
Baseline Performance (Early March)
Our initial runs established baseline performance before any RAG parameter tuning. With default configurations, the system achieved roughly 15% outcome accuracy and key-point coverage below 0.15, indicating that while the LLM could generate structurally plausible opinions, it struggled to predict actual case outcomes and surface the specific doctrinal reasoning from the gold standard.
| Run | Date | Outcome Acc. | Ideology Align. | Key-Point Cov. | LLM Judge |
|---|---|---|---|---|---|
| clean_results | Mar 2 | 15.4% | 50.0% | 0.142 | 3.83 |
| titan_results | Mar 2 | 15.4% | 50.0% | 0.115 | 3.92 |
| fixed_cohere | Mar 2 | 30.8% | 30.0% | 0.442 | 3.77 |
| fixed_titan | Mar 2 | 15.4% | 40.0% | 0.455 | 4.00 |
Early embedding provider experiments showed that Cohere embeddings yielded higher outcome accuracy (30.8%) while Amazon Titan embeddings achieved better key-point coverage (0.455) and LLM judge scores (4.00). Neither provider dominated across all metrics, motivating further tuning.
Iterative Improvement (Mid-March)
Through prompt engineering, coalition-level tuning, and evaluation pipeline refinements, we steadily improved across all metrics. The shift from evaluating 10 ideology cases to all 13 cases also provided a more comprehensive picture of alignment accuracy.
| Run | Date | Outcome Acc. | Ideology Align. | Key-Point Cov. | LLM Judge |
|---|---|---|---|---|---|
| results_1 | Mar 9 | 23.1% | 53.8% | 0.517 | 3.85 |
| results_4 | Mar 16 | 38.5% | 53.8% | 0.432 | 4.00 |
| results_5 | Mar 16 | 46.2% | 53.8% | 0.527 | 3.92 |
| results_6 | Mar 18 | 46.2% | 46.2% | 0.508 | 3.92 |
Chunk Size & Overlap Ablation
To understand how retrieval granularity affects simulation quality, we conducted an ablation study varying chunk size (cs) and chunk overlap (co) while holding all other parameters constant. This experiment isolated the impact of how we segment judicial opinions before embedding them into our FAISS vector stores.
| Configuration | Outcome Acc. | Ideology Align. | Key-Point Cov. | LLM Judge |
|---|---|---|---|---|
| cs=1000, co=100 | 15.4% | 53.8% | 0.502 | 3.92 |
| cs=1000, co=300 | 15.4% | 30.8% | 0.180 | 3.67 |
| cs=1500, co=300 | 23.1% | 53.8% | 0.459 | 4.00 |
| cs=2000, co=100 | 15.4% | 53.8% | 0.608 | 4.00 |
| cs=2000, co=300 | 46.2% | 53.8% | 0.564 | 4.00 |
The ablation revealed that larger chunk sizes (2000 tokens) consistently outperformed smaller ones, likely because legal reasoning often spans multiple paragraphs and smaller chunks fragment the doctrinal logic. The best configuration — chunk size 2000 with overlap 300 — achieved 46.2% outcome accuracy, 53.8% ideology alignment, 0.564 key-point coverage, and a perfect 4.00 LLM judge score. Notably, cs=2000 with co=100 achieved the highest raw key-point coverage (0.608) but failed to translate that retrieval quality into correct outcome predictions, suggesting that overlap size plays a critical role in maintaining contextual continuity for the generation step.
Retrieval Depth (k) Experiment
We also tested increasing the number of retrieved chunks (k=10) to determine whether surfacing more context would improve predictions. The k=10 configuration achieved 15.4% outcome accuracy with 0.484 key-point coverage — comparable to baseline rather than improved, suggesting that retrieving too many chunks can introduce noise that dilutes the most relevant precedents.
Graph RAG Evaluation
To explore whether graph-based retrieval could outperform our standard FAISS vector search, we evaluated a Graph RAG approach across three retrieval depth settings (k=5, 10, 15). Graph RAG constructs a knowledge graph from judicial opinions, enabling the retrieval of structurally connected reasoning chains rather than isolated text chunks.
| k | Outcome Acc. | Ideology Align. | Key-Point Cov. | LLM Judge |
|---|---|---|---|---|
| 5 | 23.1% (3/13) | 53.8% (7/13) | 0.527 | 3.85 |
| 10 | 15.4% (2/13) | 53.8% (7/13) | 0.409 | 3.92 |
| 15 | 38.5% (5/13) | 53.8% (7/13) | 0.511 | 3.85 |
Graph RAG at k=15 achieved 38.5% outcome accuracy, approaching the best standard RAG configuration (46.2% at cs=2000, co=300). Ideology alignment remained consistent at 53.8% across all k values. Notably, Graph RAG at k=5 achieved key-point coverage of 0.527 — competitive with the best iterative runs — suggesting that graph-structured retrieval surfaces more relevant reasoning with fewer retrieved passages. However, k=10 underperformed with only 15.4% outcome accuracy, indicating that the graph retrieval exhibits a non-monotonic relationship between retrieval depth and prediction quality.
RAGAS Retrieval Quality
To evaluate the quality of our retrieval pipeline independently from generation, we conducted a comprehensive RAGAS evaluation across 837 test records spanning all 13 cases, three chunk sizes (1000, 1500, 2000), three overlap values (100, 200, 300), three retrieval depths (k=5, 10, 15), and three query modes (liberal, conservative, combined).
| Query Mode | Context Precision | Context Recall |
|---|---|---|
| Combined (Chief Justice) | 0.856 | 0.852 |
| Conservative Coalition | 0.774 | 0.828 |
| Liberal Coalition | 0.770 | 0.640 |
| Overall Average | 0.807 | 0.784 |
The combined (Chief Justice) store achieved the highest retrieval quality across both metrics, benefiting from its access to opinions from all justices. The conservative coalition store outperformed the liberal store in recall (0.828 vs. 0.640), likely because conservative justices authored more majority opinions in the 2024–25 Term, resulting in richer and more relevant training data. Across retrieval depths, k=5 yielded the highest context recall (0.800), while k=15 showed slight degradation (0.758), reinforcing the finding that additional retrieved passages can introduce noise.
Summary of Findings
Over the course of 22 evaluation runs, we observed a roughly 3× improvement in both outcome accuracy (15.4% → 46.2%) and key-point coverage (0.115 → 0.564). Key takeaways include:
- Chunk size is the most impactful RAG parameter — larger chunks preserve the multi-paragraph reasoning structure of judicial opinions, directly improving both retrieval quality and downstream prediction accuracy.
- Overlap matters for generation, not just retrieval — higher overlap (300 vs. 100) with large chunks improved outcome accuracy even when raw coverage was slightly lower, indicating that contextual continuity between chunks aids the LLM's reasoning.
- Graph RAG shows competitive performance — at k=15, Graph RAG achieved 38.5% outcome accuracy, approaching standard RAG's best (46.2%), while at k=5 it delivered strong key-point coverage (0.527) with fewer retrieved passages, demonstrating that graph-structured retrieval can surface more targeted reasoning chains.
- Retrieval quality is strong across the pipeline — RAGAS evaluation confirmed 80.7% context precision and 78.4% context recall overall, with the combined store reaching 85.6% precision and 85.2% recall, validating that our vector stores successfully retrieve relevant judicial reasoning.
- Ideology alignment plateaued around 54% — predicting which coalition holds the majority proved more stable but harder to push beyond this ceiling, likely due to swing-vote cases where the Chief Justice sides with either bloc.
- LLM judge scores converged to 4.0 — the generated opinions are consistently rated as structurally sound and reasoning-aligned, even in cases where the predicted outcome was incorrect.
- More retrieval is not always better — increasing k beyond the default introduced noise without improving accuracy across both standard RAG and Graph RAG, reinforcing the importance of retrieval precision over volume.
Link
Acknowledgement
We would like to express our gratitude to our instructors and to our classmates in the MIDS program for continuously showing support and encouragement for our project. Without these individuals, our experiences would never have been the same. In honor of our instructors, Joyce and Korin, we named our working models after them as their feedback and guidance contributed to our success and excitement for working on such a product.
Milestones
Agents, Flow & Knowledge Base
Released AWS Bedrock Agents (Conservative & Liberal), Bedrock Flow orchestration, and Knowledge Base backed by OpenSearch Service vector database on Bedrock. Established the foundational debate infrastructure.
SageMaker on Bedrock
Completed the full SageMaker deployment pipeline — build Docker image, push to ECR, deploy real-time endpoint. Enabled self-hosted Korin inference separate from the Bedrock agent layer.
Korin 1.0
Launched the LangGraph multi-agent SCOTUS simulation engine with individual justice personas, per-justice FAISS retrievers, and research tool integration. Each justice argues independently with access to their own past opinions.
RAG Integration & Settings
Integrated FAISS vector stores into the agent pipeline. Released per-justice retrieval-augmented generation, tone level configuration (5 tiers), detail level settings (brief/in-depth), and user-selectable justice panels.
Evaluation Pipeline v1
Released the initial evaluation pipeline with outcome accuracy, ideology alignment, key-point coverage, dissent detection, vote accuracy, and LLM-as-a-judge similarity scoring.
StateGraph Visualization & Eval v2
Added interactive Mermaid and PNG visualizations of the LangGraph topology. Ran Evaluation 2.0 using the structured gold-answer dataset with per-coalition key-point scoring.
Korin 1.5 — Coalition Mode
Launched Coalition Mode (Liberal vs. Conservative coalitions) and Individual Justice Mode as dual simulation paths. Added UI settings panel, deployed Cohere and Amazon Titan endpoints, and added outcome_short to the gold-answer dataset to resolve outcome metric extraction issues.
RAGAS Evaluation
Integrated the RAGAS framework for retrieval quality assessment (context precision, context recall, faithfulness, answer relevancy). Resolved compatibility: RAGAS v0.3.x is compatible with Bedrock LLM; newer v0.4.x is not. Implemented custom JSON sanitization layer for Bedrock Claude responses.